FIR滤波器的串行与并行结构
在上一次博客Fir滤波器设计及其FPGA实现里具体阐述了如何设计FIR滤波器并在vivado上面进行仿真,这边主要是补充FIR的原理和串并行结构的差异与如何配置,以及FIR ~ IIR的差别
数字滤波器 ~ FIR、IIR
- FIR - 线性相位、消耗资源多
- IIR非线性相位、消耗资源少
提到线性相位必然就要谈谈相噪的问题,例如在接收机中,针对AM、DSB调制信号的解调都需要同频同相的载波信号(如果基带信号不是单频的话!),如果是IIR的非线性相位,那么各频率成分的相对相位就会产生偏移,也就是会造成丢失基带信号的部分信息的结果,解调信号也就可能不是我们要的了。
采用FIR滤波器可以保证各频率成分的信号之间,相位是相对固定的同时保证输入信号的延时特性。
不过如果在只关心频率成分的系统中,也可以采用节省资源的IIR滤波器
FIR 滤波器原理
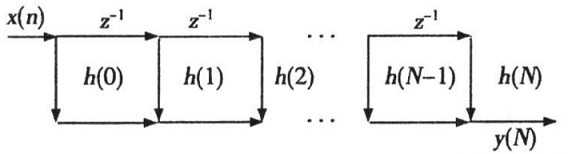
- FIR的系统相应h(N)是一个N点的有限长序列,我们通过观察上次在MATLAB仿真的代码,也可以得知输出本质上就是信号与h(N)的卷积(时域的卷积等于频域的相乘),所以我们实际上可以把FIR滤波器看成是一个智能的衰减器,其筛选频谱中各频率分量的增益倍数(滤波器系数),有些被保留而有些被衰减,从而实现滤波的效果
FIR滤波器的串并行结构
其使用n/2(借助线性相位FIR滤波器的h(N)的对称性)个乘法器同时做乘法,再将结果累加作为FIR滤波输出。这样的好处就是每个时钟其都能完成一次运算,得到一个输出结果。不过其缺点也比较明显,就是资源占用较大,同时会随着FIR阶数的增加不断扩大资源占用
串行FIR通过增加计算周期来减少资源占用,仅使用一个乘法器执行数据和系数的乘法,同时累加器不断累加。因此需要n/2个时钟才能完成运算,再由加法器数量细分,其还可以分为全串行 or 半串行
- 总的来说,就是并行结构主要是牺牲资源,提高运算速度;而串行结构主要就是以增大计算周期来节省资源
串行、并行结构 vivado 配置
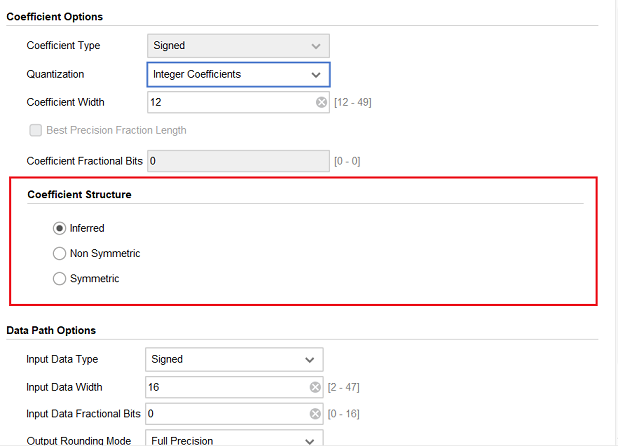
Inferred - IP核根据设计的参数和限制条件,自动选择最佳的实现方式,以最大限度地利用可用资源和满足性能要求,但不一定适用于所有的设计场景,如果是对于滤波器性能和计算结构有特殊要求的应用。如果最后滤波器失效,也有一定的可能性是因为Inferred自动生成的代码,出现些许错误(不过一般不可能错)
Symmetric - 串行结构(对称系数结构),其内部是将所有系数按照正序和反序分别存储在两个ROM中,优劣点上面已经提过了
Non Symmetric - 并行结构(非对称结构),虽然其可以提高运算速度,不过需要注意的是使用并行结构会产生更多的时序问题,也就是说需要更复杂的时序分析和约束,以确保稳定性和正确性
总结
一般来说通信题中我们可能就是在最后解调信号输出端接一个FIR的LPF,就是性能别卡得太死(别追求纯理想滤波器),一般直接选择Inferred(至少我目前测试一些几百阶的它还很好,而且我们又没有特殊需求)